هر روز به تعداد ماشینهایی که مانند انسان فکر و عمل میکنند، اضافه میشود اما آیا میدانید این ماشینها چگونه میتوانند مهارتهای گوناگون را یاد بگیرند؟ آنها معمولاً از الگوریتم های یادگیری عمیق برای این کار کمک میگیرند.
یادگیری عمیق در محاسبات علمی محبوبیت زیادی به دست آورده است و الگوریتم های یادگیری ماشین و عمیق به طور گسترده توسط صنایعی که با مسائل پیچیدهای سروکار دارند، استفاده میشود. همه الگوریتم های یادگیری عمیق از انواع مختلفی از شبکههای عصبی برای انجام وظایف خاص استفاده میکنند اما این الگوریتمها چه نام دارند و کاربرد هر یک چیست؟ در این مقاله به بررسی نحوه عملکرد شبکههای یادگیری عمیق پرداخته و چگونگی تقلید آنها از مغز را شرح میدهیم.
دیپ لرنینگ یا یادگیری عمیق مانند سفر جذابی به دنیای هوش مصنوعی است. برای درک بهتر این موضوع ابتدا بیایید به نحوه یادگیری انسانها نگاهی بیندازیم. مغز انسان هر روز از طریق مواجهه با تجربیات جدید رشد میکند. وقتی نوزادان دیدن، شنیدن، بوییدن و حتی لامسه را تجربه میکنند، مغز آنها بهسرعت الگوها و قوانین جهان را درک میکند و بهمرور زمان آموزش میبیند. همین ایده در دیپ لرنینگ نیز وجود دارد.
در دیپ لرنینگ، مدلهای کامپیوتری توسط دادههای بزرگ و متنوع آموزش داده میشوند. این مدلها، همانند انسانها که از تجربیات خود استفاده میکنند تا جهان را درک کنند، سعی دارند با کمک الگوها و اطلاعات دادهای موجود به صورت خودکار یاد بگیرند. برای مثال، بهمرورزمان یاد میگیرند که زبانها را ترجمه کنند.
بنابراین، دیپ لرنینگ مسیر هیجانانگیزی بهسوی ایجاد مدلهای هوشمند و توانمند است که تواناییهای یادگیری از دادههای پیچیده را دارند، مانند انسانها که از تجربیات زندگی خود یاد میگیرند.
یادگیری عمیق یا دیپ لرنینگ (Deep Learning) از شبکههای عصبی مصنوعی برای انجام محاسبات پیچیده بر روی مقادیر زیادی داده استفاده میکند. یادگیری عمیق نوعی یادگیری ماشینی است که بر اساس ساختار و عملکرد مغز انسان کار میکند اما برای یادگیری از شبکهها یا الگوریتمهایی کمک میگیرد.
الگوریتم های یادگیری عمیق، ماشینها را از طریق مثالهایی ملموس آموزش میدهند. پس از آموزش ماشینها میتوان از یادگیری عمیق در پزشکی، مراقبتهای بهداشتی، تجارت الکترونیک، سرگرمی و تبلیغات استفاده کرد.
انواع الگوریتم های یادگیری عمیق
الگوریتمها و شبکههای مختلفی برای دیپ لرنینگ وجود دارد که در این مقاله میخواهیم ۱۰ مورد از برترین الگوریتم های یادگیری عمیق را به شما معرفی کنیم.
شبکههای عصبی کانولوشن (CNN)
شبکههای حافظه کوتاهمدت (LSTM)
شبکههای عصبی بازگشتی (RNN)
شبکههای مولد تخاصمی (GAN)
شبکههای تابع پایه شعاعی (RBFN)
پرسپترونهای چند لایه (MLP)
نقشههای خودسازماندهی (SOM)
شبکههای باور عمیق (DBN)
ماشینهای محدود بولتزمن (RBM)
رمزگذاریهای خودکار (Autoencoders)
الگوریتم های یادگیری عمیق تقریباً با هر نوع دادهای کار میکنند و برای حل مسائل پیچیده به مقادیر زیادی از قدرت و اطلاعات محاسباتی نیاز دارند اما این الگوریتمها چه هستند؟ بیایید با هر یک از شبکهها یا همان الگوریتم های یادگیری عمیق آشنا شویم.
شبکههای عصبی کانولوشن (CNN)
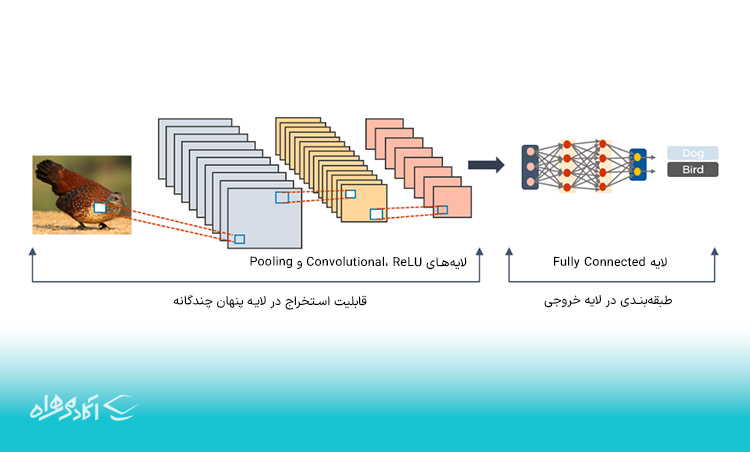
شبکههای سیانان که بهعنوان ConvNet نیز شناخته میشوند، عمدتاً از چندین لایه تشکیل شدهاند و به طور خاص برای پردازش تصویر و تشخیص اشیا استفاده میشوند. این نوع شبکه در سال ۱۹۹۸ توسط Yann LeCun توسعه یافت و اولینبار LeNet نام گرفت. در آن زمان، شبکههای CNN برای تشخیص ارقام و کاراکترهای کد پستی توسعه یافت ولی امروزه، CNNها در شناسایی تصویر ماهوارهها، پردازش تصویر پزشکی، پیشبینی سریال و تشخیص ناهنجاریها، کاربرد گستردهای دارند.
CNNها دادهها را با عبور از لایههای متعدد و استخراج ویژگیها، پردازش میکنند. این لایهها عبارتاند از Convolutional، ReLU، Pooling و Fully Connected.
لایه Convolutional دارای چندین فیلتر برای انجام عملیات کانولوشن است. لایه ReLU نقشه عملیات را تصحیح کرده و برای انجام عملیات بر روی عناصر استفاده میشود. خروجی آن نیز یک نقشه ویژگی اصلاح شده است.
در مرحله بعد، لایه ادغام (Pooling) توسط نقشه ویژگی اصلاح شده تغذیه میشود. Pooling یک عملیات نمونهبرداری سطح پایین است که ابعاد نقشه ویژگی را کاهش میدهد. نتیجه تولید شده شامل آرایههای دو بعدی متشکل از بردار منفرد، بلند، پیوسته و خطی است که در نقشه ویژگی کشیده شدهاند.
لایه بعدی یعنی لایه کاملاً متصل (Fully Connected) نامیده میشود. این لایه، ماتریس مسطح یا آرایه دوبعدی را تشکیل میدهد که دادهها را از لایه Pooling به عنوان ورودی دریافت و تصاویر را شناسایی میکند.
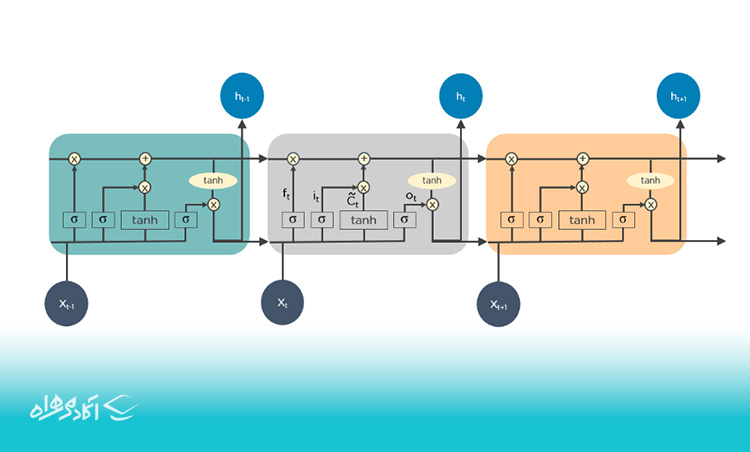
LSTMها نیز از جمله الگوریتم های یادگیری عمیق به شمار میروند که به عنوان نوعی شبکه عصبی بازگشتی (RNN) شناخته میشوند. این نوع شبکهها برای یادگیری و سازگاری با دادههای پیوسته، مانند سریهای زمانی و متن یا صدا برنامهریزی شدهاند و میتوانند دادههای گذشته را برای مدتزمان بیشتری بهخاطر بسپارند.
LSTMها میتوانند اطلاعات را در طول زمان ذخیره و بازیابی کنند که به آنها امکان میدهد الگوهای پیچیدهای را در دادهها شناسایی کنند.
LSTMها از سه نوع دروازه تشکیل شدهاند:
دروازه فراموشی: این دروازه تعیین میکند که چه مقدار از اطلاعات موجود در سلول باید حفظ شود.
دروازه ورودی: این دروازه تعیین میکند که چه مقدار اطلاعات جدید باید به سلول اضافه شود.
دروازه خروجی: این دروازه تعیین میکند که چه مقدار از اطلاعات موجود در سلول باید به عنوان خروجی ارسال شود.
LSTMها با استفاده از این دروازهها، میتوانند اطلاعات را در طول زمان ذخیره و بازیابی کنند. علاوه بر کاربردهای پیشبینی سریهای زمانی، میتوان از آنها برای ساخت تشخیصدهنده گفتار، توسعه در داروسازی و ترکیب حلقههای موسیقی استفاده کرد.
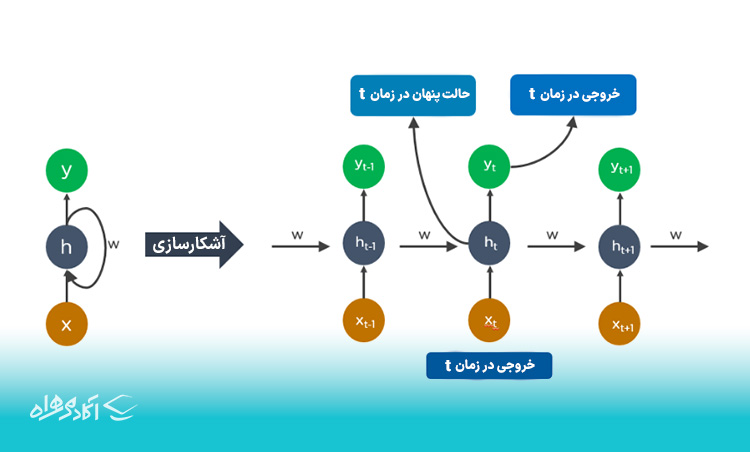
شبکههای عصبی بازگشتی (RNN)
شبکههای عصبی بازگشتی یا RNN از برخی اتصالات جهتدار تشکیل شدهاند که چرخهای را به وجود میآورند که اجازه میدهد ورودی ارائهشده از LSTMها به عنوان ورودی در فاز فعلی RNN استفاده شود. این ورودیها توانایی به خاطر سپاری LSTMها را تقویت میکنند. بنابراین RNNها به ورودیهایی وابسته هستند که توسط LSTMها حفظ میشوند و تحت پدیده همگامسازی LSTMها کار میکنند.
Unfold: آشکارسازی
Hidden state at time t: حالت پنهان در زمان t
Output at time t: خروجی در زمان t
Input at time t: ورودی در زمان t
RNNها بیشتر در زیرنویس کردن تصویر، تجزیهوتحلیل سریهای زمانی، تشخیص دادههای دستنویس و ترجمه دادهها به ماشین استفاده میشوند.
اگر زمان به صورت t تعریف شده باشد، در یک RNN، خروجی یک واحد در زمان t به عنوان ورودی برای همان واحد در زمان t+1 استفاده میشود. این ویژگی به RNN اجازه میدهد تا اطلاعات را در طول زمان ذخیره و بازیابی کند.
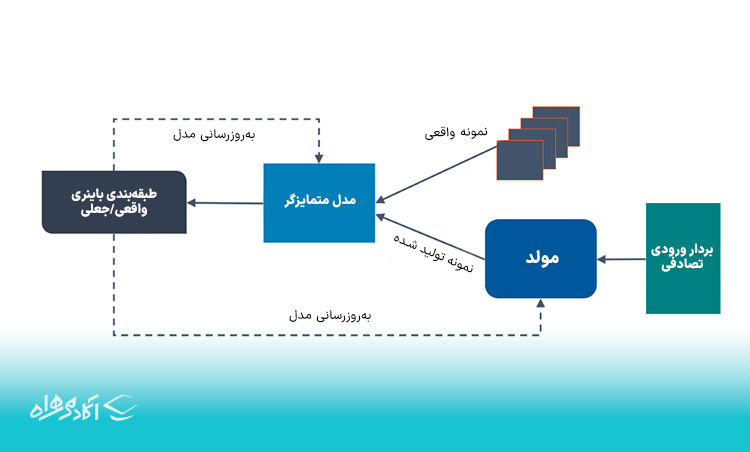
شبکههای مولد تخاصمی (GAN)
GANها به عنوان نوع خاصی الگوریتم های یادگیری عمیق تعریف میشوند که برای تولید نمونههای جدیدی از دادهها که با دادههای آموزشی مطابقت دارند، استفاده میشود. GAN معمولاً از دو جزء تشکیل شده است؛ یک مولد که یاد میگیرد دادهها را تولید کند و یک متمایزگر که دادههای واقعی را از دادههای تولید شده توسط مولد تشخیص میدهد.
GANها به دلیل استفاده مکرر برای شفافسازی تصاویر نجومی و سایر عملیات، کاربرد زیادی پیدا کردهاند. همچنین در بازیهای ویدیویی برای افزایش گرافیک بافتهای دو بعدی با بازآفرینی آنها در وضوح بالاتر مانند 4K استفاده میشود. علاوه بر این، در ایجاد شخصیت کارتونی واقعگرایانه و همچنین رندر چهره انسان و اشیاء سه بعدی به خوبی عمل میکنند.
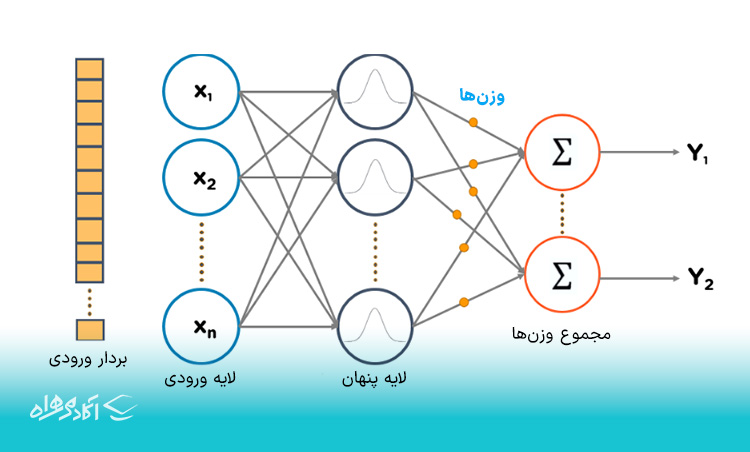
شبکههای تابع پایه شعاعی (RBFN)
RBFNها انواع خاصی از شبکههای عصبی هستند که از یک رویکرد پیشخور (feed-forward) پیروی کرده و از توابع شعاعی به عنوان توابع فعالسازی استفاده میکنند. آنها از سه لایه به نامهای لایه ورودی، لایه پنهان و لایه خروجی تشکیل شدهاند که بیشتر برای پیشبینی سریهای زمانی، آزمایش رگرسیون و طبقهبندی استفاده میشوند.
Input Vector: بردار ورودی
Input Layer: لایه ورودی
Hidden Layer: لایه پنهان
Weighted sums: مجموع وزنها
شبکههای تابع پایه شعاعی، وظایف خود را با اندازهگیری شباهتهای موجود در مجموعهدادههای آموزشی، انجام میدهند. در واقع، RBFN از آزمونوخطا برای تعیین ساختار شبکه استفاده میکند که در دو مرحله انجام میشود:
در مرحله اول، مراکز لایه پنهان با استفاده از الگوریتم یادگیری بدون نظارت (k-means clustering) تعیین میشوند.
در مرحله بعد وزنها با رگرسیون خطی تعیین میشوند. میانگین مربعات خطا (MSE) برای تعیین خطا استفاده میشوند و وزنها بر این اساس بهینهسازی شده تا MSE به حداقل برسد.
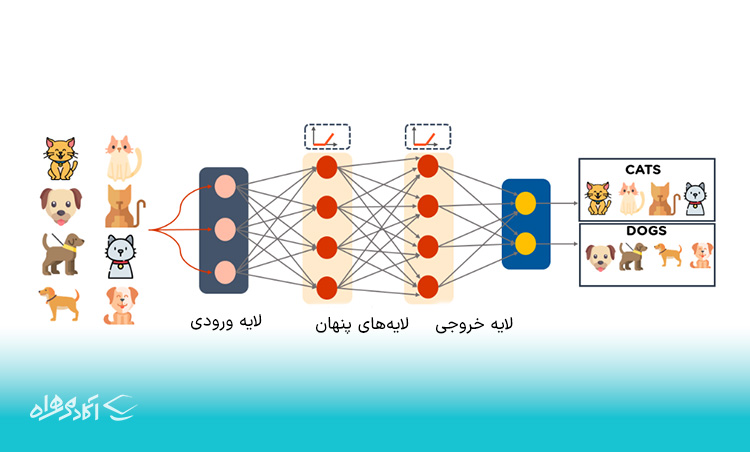
پرسپترونهای چندلایه (MLP)
MLP ابتداییترین مدل از الگوریتم های یادگیری عمیق و همچنین یکی از قدیمیترین تکنیکهاست. اگر در یادگیری عمیق مبتدی هستید و بهتازگی کاوش در آن را آغاز کردهاید، توصیه میکنیم با MLP شروع کنید. MLPها را میتوان به عنوان شکلی از شبکههای عصبی feed-forward نام برد. عملکرد MLP به شرح زیر است:
Input Layer: لایه ورودی
Hidden Layers: لایههای پنهان
Output Layer: لایه خروجی
لایه اول یعنی لایه ورودی، ورودیها را میگیرد و آخرین لایه بر اساس لایههای پنهان، خروجی را تولید میکند. هر گره به گرههای موجود در لایه بعدی متصل است. بنابراین، اطلاعات به طور مداوم بین لایههای متعدد به جلو منتقل میشود. به همین دلیل است که به آن شبکه پیشخور (feed-forward) گفته میشود.
MLP از یک تکنیک یادگیری نظارت شده رایج به نام «پس انتشار (backpropagation) برای آموزش» استفاده میکند. هر لایه پنهان با مقداری وزن (مقادیر اختصاصدادهشده به طور تصادفی) تغذیه میشود. سپس، ترکیبی از وزن و ورودی به یک تابع فعالسازی ارائه میشود که برای تعیین خروجی به لایه بعدی منتقل شود. پس از این کار، اگر به خروجی مورد انتظار نرسیدیم، ضرر (خطا) را محاسبه میکنیم و برای بهروزرسانی وزنها به عقب برمیگردیم. این فرایندی تکراری است تا زمانی که خروجی پیشبینی شده (با آزمونوخطا) به دست آید.
MLPها معمولاً از توابع سیگموئید، واحد خطی اصلاح شده (ReLU) و tanh به عنوان توابع فعالسازی استفاده میکنند.
شبکههای MLP توسط رسانههای اجتماعی (مانند اینستاگرام و فیسبوک) برای فشردهسازی دادههای تصویر استفاده میشوند تا به بارگذاری سریعتر تصاویر کمک کنند. کاربردهای دیگر این مدل از الگوریتم های یادگیری عمیق عبارتاند از استفاده در تشخیص تصویر و گفتار، فشردهسازی دادهها و حل مشکلات طبقهبندی.
تصور کنید با یک مجموعهداده از صدها ویژگی کار میکنید و میخواهید دادههای خود را برای درک ارتباط بین هر ویژگی، در ابعاد کوچکتری تجسم کنید. تصور آن توسط انسانها یا با استفاده از نمودارهای پراکنده یا زوجی ممکن نیست. اینجا الگوریتم یادگیری عمیق SOM به میان میآید. SOM با کاهش ابعاد دادهها به ما کمک میکند توزیع مقادیر ویژگی را تجسم کنیم. منظور از کاهش ابعاد، حذف ویژگیهایی است که ارتباط کمی با یکدیگر دارند.
SOMها دادههای مشابه را با ایجاد یک نقشه یکبعدی یا دوبعدی، با هم گروهبندی میکنند. همانند سایر الگوریتمها، در SOM نیز وزنها به صورت تصادفی برای هر گره، مقداردهی اولیه میشوند. در هر مرحله، یک نمونه بردار (X)، به طور تصادفی از مجموعهدادههای ورودی گرفته شده و فاصله بین X و سایر بردارها محاسبه میشود.
پس از رأیگیری، بهترین واحد تطبیق (BMU) نزدیک به X، از بین تمام بردارهای دیگر انتخاب میشود. هنگامی که BMU شناسایی شد، بردارهای وزن بهروز شده و BMU و همسایگان توپولوژیکی آن به بردار ورودی X نزدیکتر میشوند. این فرآیند تا زمانی که خروجی مورد انتظار را به دست آوریم، تکرار میشود.
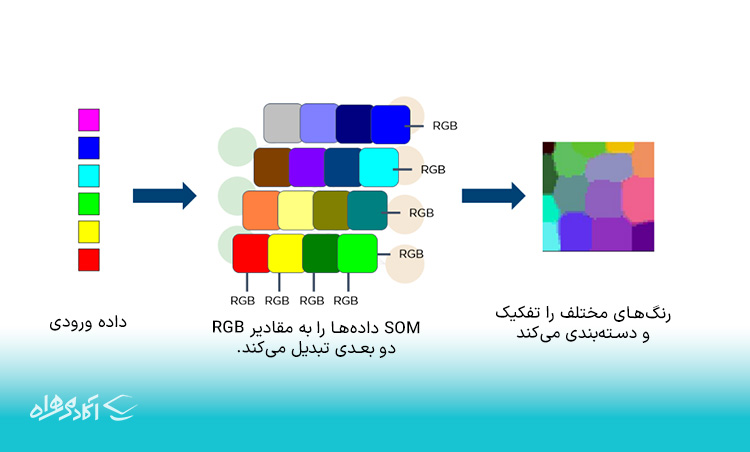
برای مثال، یک بردار ورودی با رنگهای مختلف را تصور کنید. این دادهها به یک SOM تغذیه میشوند و سپس SOM دادهها را به مقادیر RGB دو بعدی تبدیل میکنند. در نهایت رنگهای مختلف را از هم جدا و دستهبندی میکنند.
Input data: داده ورودی
SOM Converts the data into 2D RGB values :SOM دادهها را به مقادیر RGB دو بعدی تبدیل میکند.
Segregates and categorizes the diffrent colors: رنگهای مختلف را تفکیک و دستهبندی میکند.
کاربردهای الگوریتم SOM عبارتاند از تجزیهوتحلیل تصویر، تشخیص خطا، نظارت و کنترل فرایند و غیره. SOMها به دلیل تواناییشان در ایجاد تجسمهای قدرتمند، برای مدلسازی سهبعدی سر انسان با استفاده از تصاویر استریو استفاده میشوند. همچنین، این مدل خاص از الگوریتم های یادگیری عمیق در بخش مراقبتهای بهداشتی برای ایجاد نمودارهای سهبعدی بسیار کاربردی هستند.
شبکههای باور عمیق (DBN)
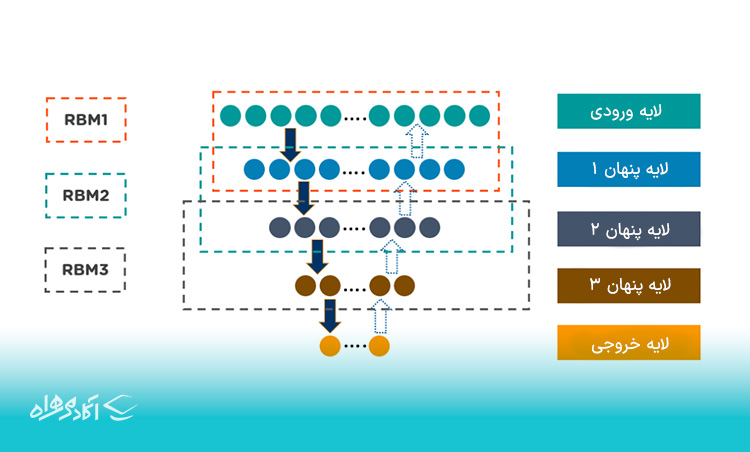
یک شبکه باور عمیق (DBN) با الحاق چندین لایه ماشین بولتزمن محدود شده (RBM) ساخته میشود. هر لایه RBM میتواند با لایههای قبلی و بعدی خود ارتباط برقرار کند.
DBNها با استفاده از الگوریتم Greedy از قبل آموزش داده شدهاند. این الگوریتم از یک رویکرد لایه به لایه برای یادگیری تمام وزنهای مولد استفاده میکند. جالب است بدانید که در این مدل خاص از الگوریتم های یادگیری عمیق همه متغیرهای یکلایه به متغیرهای دیگر در لایه بالایی متکی هستند.
Input Layer: لایه ورودی
Hidden Layer 1: لایه پنهان ۱
Hidden Layer 2: لایه پنهان ۲
Hidden Layer 3: لایه پنهان ۳
Output Layer: لایه خروجی
چندین مرحله از نمونهبرداری گیبس (Gibbs) در دو لایه پنهان بالای شبکه، اجرا میشوند. ایده این کار این است که یک نمونه از RBM که توسط دو لایه پنهان بالا تعریف شده است، ترسیم کنیم. در مرحله بعد، از یک گذر نمونهبرداری اجدادی (Ancestral Sampling) کمک بگیریم تا نمونهای از واحدهای قابلمشاهده را تهیه کنیم.
یک گذر از پایین به بالا میتواند به یادگیری مقادیر متغیرهای پنهان در هر لایه منجر شود. پیش آموزش Greedy نیز از بردار داده مشاهده شده در پایینترین لایه شروع میشود. سپس این الگوریتم با کمک fine-tuning از وزنهای مولد در جهت مخالف استفاده میکند.
کاربردهای الگوریتم DBN نیز عبارتاند از تشخیص، خوشهبندی، ایجاد تصاویر، توالیهای ویدیویی و دادههای موشن کپچر.
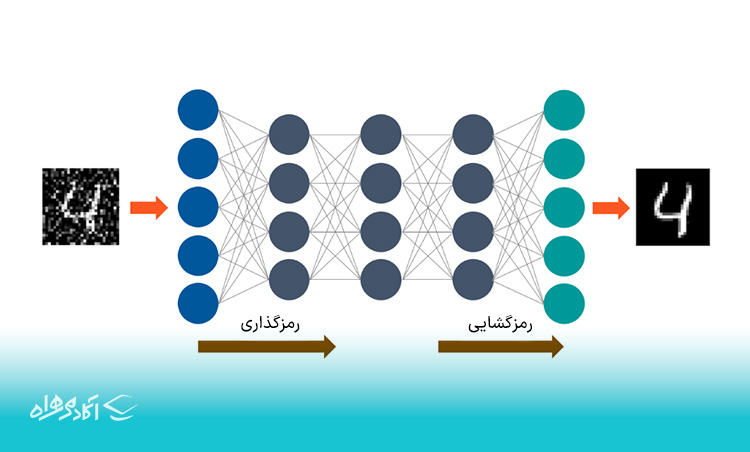
رمزگذاری خودکار (Autoencoders)
رمزگذاری خودکار نوع خاصی از الگوریتم های یادگیری عمیق و شبکههای عصبی است که ورودیهای آن معمولاً با خروجیهایشان یکسان است. این برنامه عمدتاً برای حل مشکلات مربوط به یادگیری بدون نظارت طراحی شده است. رمزگذارهای خودکار، شبکههای عصبی آموزشدیدهای هستند که دادهها را تکرار میکنند. به همین دلیل است که ورودیها و خروجیها بهطورکلی یکسان هستند. آنها برای دستیابی به وظایفی مانند کشف دارو، پردازش تصویر و پیشبینی جمعیت استفاده میشوند.
رمزگذارهای خودکار شامل سه جزء به نامهای انکدر، کد و دیکودر هستند. آنها ساختاری دارند که میتوانند ورودیها را دریافت کرده و به خروجیهای مختلف تبدیلشان کنند. آنها این کار را با رمزگذاری تصویر یا ورودی و کاهش اندازه آن انجام میدهند. اگر تصویر بهدرستی قابلمشاهده نباشد، برای شفافسازی به شبکه عصبی ارسال میشود. سپس، تصویر شفاف شده را یک عکس بازسازی شده مینامند و این دقیقاً شبیه به تصویر قبلی است. برای درک این فرآیند پیچیده، نمودار زیر را ببینید.
یادگیری عمیق در طول پنج سال گذشته تکامل یافته و الگوریتم های یادگیری عمیق در بسیاری از صنایع به طور گستردهای محبوب شدهاند چرا که به کمک این الگوریتمها میتوان به ماشینها انجام عملیات مختلف را یاد داد. ماشینها به طور مداوم توسط این الگوریتمها آموزش میبینند تا در نهایت مانند یک انسان عمل کنند اما این کار چگونه امکانپذیر است؟ در دوره بوت کمپ پایتون و هوش مصنوعی به طور کامل به آموزش الگوریتم های یادگیری عمیق پرداختهایم. با گذراندن این دوره میتوانید اطلاعات بسیار خوبی در این زمینه به دست آورید و وارد دنیای جذاب هوش مصنوعی و یادگیری عمیق شوید.