



شیب پیشرفت هوش مصنوعی و بهخصوص یادگیری ماشین در سالهای اخیر بسیار تند است! دیگر نمیتوانید به اطراف خود نگاهکنید و اثری از یادگیری ماشین نبینید. از الگوریتم موتورهای جستوجو برای رتبهبندی سایتها گرفته تا قفل گوشیتان که فقط با چهره شما باز میشود، همه و همه از دستاوردهای یادگیری ماشین است. اما آیا تا بهحال فکرکردهاید که الگوریتم های یادگیری ماشین چطور از پس این عملیاتهای پیچیده برمیآیند؟ در این مقاله با تشریح ساده ۱۰ الگوریتم مهم یادگیری ماشین به این سوال جواب میدهیم و در ادامه راهی عالی برای یادگیری کامل الگوریتمها را معرفی میکنیم.
حتی اگر تعریف درستی از ماشین لرنینگ در ذهن ما نباشد و الگوریتمهای یادگیری ماشین را نشناسیم، همه روزه با آنها سروکار داریم. اگر بخواهیم یک تعریف ساده از ماشین لرنینگ داشته باشیم:
ماشین لرنینگ یا یادگیری ماشین یک شاخه از هوش مصنوعی است که به ماشینها امکان میدهد بدون برنامهنویسی صریح، از دادهها یاد بگیرند.
در یادگیری ماشین، الگوریتمها از دادههای نمونه یا آموزشی برای ایجاد یک مدل ریاضی استفاده میکنند که میتوان از آن برای پیشبینی یا تصمیمگیری استفاده کرد.
خطا: کاربر درخواست HTTP را بلوکه نمود.
الگوریتم های یادگیری ماشین در داده کاوی را میتوان به روشهای متنوعی دستهبندی کرد. اما اگر بخواهیم بر اساس نوع یادگیری این الگوریتمها را در دستهبندیهای مختلف قرار دهیم به ۴ نوع اصلی میرسیم:
در الگوریتم های یادگیری ماشین نظارت شده، در ابتدا دادههایی که از قبل خروجی صحیح آنها مشخص است، شروع به آموزش مدل میکنیم. به این دادهها اصلاحا برچسبگذاری شده میگوییم. برای مثال اگر ۱۰۰ نمونه عکس تومور داریم، ۵۰ نمونه را با جواب صحیح سرطانی بودن یا نبودشان به خورد مدل میدهیم.
با استفاده از دادههای آموزشی، الگوریتم، الگوی بین دادهها را کشف و سپس تابعی تولید میکند که ورودیهای جدیدی که از قبل جواب درست آنها را نمیداند به خروجی صحیح برساند.
فرآیند آموزش هم تا زمانی ادامه پیدا میکند که مدل به سطح خوبی از دقت در دادههای آموزشی برسد.
بعضی از الگوریتمهای یادگیری نظارتشده عبارتند از:
یادگیری تحت نظارت بهطور گسترده در حوزههای مختلف، از جمله مراقبتهای بهداشتی، مالی، بازاریابی و تشخیص تصویر، برای پیشبینی و بدست آوردن الگوهای ارزشمند از دادهها استفاده میشود.
الگوریتم های یادگیری ماشین بدون نظارت، دادههای بدون برچسب را فارغ از خروجیهای از پیش تعریفشده تجزیه و تحلیل میکنند. هدف کشف الگوها، روابط یا ساختارهای درون دادهها است.
خطا: کاربر درخواست HTTP را بلوکه نمود.
برخلاف یادگیری نظارتشده، الگوریتم های یادگیری ماشین بدون نظارت مستقل عمل کرده، الگوهای پنهان را کشف و دادههایی که نقاط مشترک دارند را در یک گروه قرار میدهند.
این الگوریتم برای سیستمهای پیشنهاد دهنده (مثل وقتی که یک کالا را به سبدخرید خود اضافه میکنید و بعد پیشنهادهای مشابه دریافت میکنید) یا گروهبندی مشتریها به گروههای مختلف بهخصوص برای اهداف تبلیغاتی استفاده میشود.
الگوریتمهای یادگیری بدون نظارتشده عبارتند از:
از ترکیب دو روش بالا، الگوریتم های یادگیری ماشین نیمهنظارتشده متولد میشود که هم از دادههای برچسبدار و هم بدون برچسب برای آموزش استفاده میکند. در این روش، سعی میشود از تعداد کمتری از دادههای برچسبدار و مجموعه بزرگتری از دادههای بدون برچسب برای بهبود فرایند یادگیری استفاده شود.
خطا: کاربر درخواست HTTP را بلوکه نمود.
دلیلش هم این است که دادههای بدون برچسب، اطلاعات و زمینه بیشتری را برای افزایش درک و عملکرد مدل ارائه میدهند. یادگیری نیمهنظارتشده با استفاده مؤثر از دادههای بدون برچسب، میتواند بر محدودیتهایی که استفاده مطلق از دادههای برچسبدار دارد؛ غلبه کند. برای مثال اگر تهیه دادههای برچسبدار گران یا وقتگیر باشد، این روش شما را نجات خواهد داد و چند مرحله جلو میاندازد.
تکنیکهای یادگیری نیمهنظارتشده میتوانند برای وظایف مختلفی مانند طبقهبندی، رگرسیون و تشخیص ناهنجاری استفاده شوند و به مدلها اجازه دهند پیشبینیهای دقیقتری انجام دهد تا در سناریوهای دنیای واقعی بهتر تعمیم پیدا کنند.
همانطور که یک نوزاد در ابتدای زندگی خود با آزمون، خطا، تشویق یا جریمه والدینش شروع به یادگیری میکند، ماشینها نیز میتوانند با یادگیری تقویتی، یاد بگیرند.
در الگوریتم های یادگیری ماشین تقویتی، عامل با محیطی تعامل میکند و میآموزد که چگونه تصمیمات بهینهای بگیرد تا پاداشش را حداکثر و جریمهاش را حداقل کند.
یادگیری تقویتی معمولاً در رباتیک، بازیها و سیستمهای خودران استفاده میشود. این روش به ماشینها امکان میدهد از تجربیاتشان بیاموزند، با محیطهای در حال تغییر سازگار شوند و از طریق یک سری اقدامات به اهداف بلندمدت دست یابند.
یادگیری الگوریتم های حیاتی در یادگیری ماشین، دریچه ای نو از دانش و مهارت را به روی شما باز میکند و به ارتقای تواناییهایتان در این زمینه کمک میکند. به کمک این الگوریتمها مدلهای پیشبینی دقیقتری خواهید داشت که مقیاسپذیری بالایی هم دارند.
جدا از اینها با استفاده از الگوریتمها، درک شما از دنیای اطرافتان بالا میرود و به شما کمک میکند تا مهارتهای تفکر انتقادی و حل مسئله خود را ارتقا دهید.
در ادامه لیستی از ۱۰ الگوریتم مهم را بررسی میکنیم:
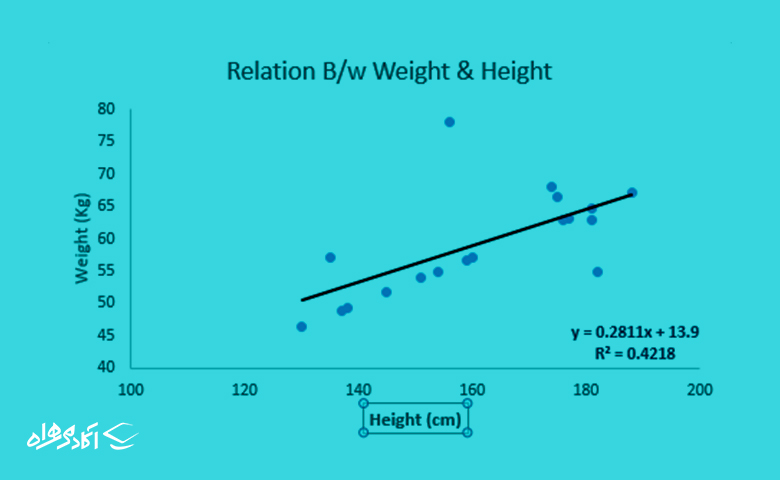
یکی از معروفترین و سادهترین الگوریتم های یادگیری ماشین رگرسیون خطی است. ابتدا این الگوریتم را با یک مثال توضیح میدهیم تا راحتتر آن را درک کنید. فرض کنید بدون اینکه وزن واقعی افراد را بدانید، مجبورید آنها را بر اساس وزن مرتب کنید، در این شرایط چه میکنید؟ احتمالا فاکتورهای دیگر مثل قد و عرض فرد(پارامترهای بصری) را در نظر میگیرید و براساس آن تحلیل میکنید. رگرسیون خطی هم همین کار را میکند!
درواقع در الگوریتم رگرسیون خطی، معادله خط بین متغیر وابسته (Y) و متغیر مستقل (X) بهوجود میآید که مقدار متغیر وابسته را با توجه به متغیر مستقل پیشبینی میکند.
معادله خطی رگرسیون به صورت زیر است:
y = ax + b
در این معادله:
y مقدار متغیر وابسته است.
x مقدار متغیر مستقل است.
a و b ضرایب رگرسیون هستند.
این ضرایب a و b با به حداقل رساندن مجذور اختلاف فاصله بین نقاط داده و خط رگرسیون به دست میآیند.
به مثال زیر نگاه کنید. در اینجا ما بهترین خط را با معادله خطی y=0.2811x+13.9 شناسایی کردهایم. حال با استفاده از این معادله میتوانیم وزن را با دانستن قد یک فرد پیدا کنیم.
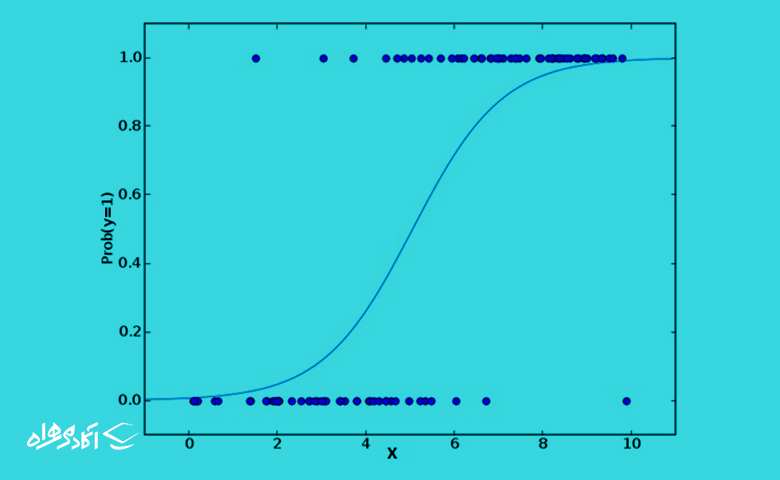
رگرسیون لجستیک برخلاف اسمش یکی از الگوریتم های یادگیری ماشین مخصوص طبقهبندی است که برای پیشبینی مقادیر باینری (مثل ۰ و ۱، True و False، بله و خیر) استفاده میشود.
به زبان سادهتر، این الگوریتم احتمال وقوع رویدادی را با پردازش دادهها به یک تابع لجستیک پیشبینی میکند و خب همانطور که انتظار میرود جواب تابع هم بین ۰ تا ۱ قرار دارد.
برای روشن شدن موضوع با یک مثال ادامه میدهیم؛ فرض کنید میخواهیم احتمال اینکه بیماری مبتلا به سرطان باشد را پیشبینی کنیم. در این مثال، متغیر وابسته سرطان (دودویی) است و متغیرهای مستقل میتوانند سن، جنسیت، سابقه خانوادگی و … باشند.
با استفاده از رگرسیون لجستیک میتوانیم مدلی ایجاد کنیم که باتوجه به مقادیر متغیرهای مستقل، احتمال سرطان را پیشبینی کند. به عنوان مثال، اگر مدل پیشبینی کند که احتمال سرطان برای یک بیمار ۰٫۸ است، یعنی این بیمار ۸۰٪ احتمال دارد که سرطان داشته باشد.
درخت تصمیم یکی از مهمترین الگوریتم های ماشین لرنینگ تحت نظارت است که در مسائل طبقهبندی و رگرسیون از آن استفاده میشود.
این الگوریتم شبیه فلوچارت است که با یک گره ریشه شروع میشود و سوال خاص در مورد دادهها میپرسد. بر اساس پاسخ، دادهها به شاخههای مختلف به سمت گرههای داخلی بعدی هدایت میشوند. در گرههای جدید دوباره سوالات بیشتری پرسیده میشود و به همین ترتیب دادهها به شاخههای بعدی هدایت میکنند. این فرآیند تا زمانی ادامه مییابد که دادهها به گره پایانی، که به عنوان گره برگ نیز شناخته میشود، برسند؛ جایی که دیگر هیچ شاخهای وجود ندارد.
خطا: کاربر درخواست HTTP را بلوکه نمود.
یک درخت تصمیم برای پستاندار بودن موجود زنده میتواند بهصورت زیر باشد:
گره ریشه:
آیا موجود مو دارد؟
بله: ادامه
خیر: پستاندار نیست
گره داخلی:
آیا موجود شیر تولید میکند؟
بله: پستاندار است
خیر: ادامه
آخرین گره داخلی(برگ):
آیا موجود تخم میگذارد؟
خیر: پستاندار است
بله: پستاندار نیست
البته این مثال بسیار ساده است و فقط برای درک موضوع آورده شده.
الگوریتم Support Vector Machine یا همان بردار پشتیبان است که برای طبقهبندی دادهها استفاده میشود. دلیل محبوبیت SVM بین دیگر الگوریتم های یادگیری ماشین، قابل اعتماد بودن و توانایی کار با حجم دادههای کم است.
این الگوریتم با کشیدن یک مرز تصمیم بهنام ابرصفحه (hyperplane) دادهها را از هم جدا میکند.
هدف الگوریتم SVM این است که بهترین مرز تصمیم ممکن با به حداکثر رساندن حاشیه بین دو مجموعه داده برچسبگذاری شده را پیدا کند و بزرگترین شکاف یا فاصله بین کلاسها را بیابد.
ابرصفحه در فضای دو بعدی به شکل خط است اما هرچه ویژگیهای مورد استفاده بیشتر باشد، تعداد ابعاد افزایش پیدا کرده و الگوهای پیچیدهتری تشکیل میدهد.
یکی دیگر از الگوریتم های یادگیری ماشین بیز ساده است. این الگوریتم طبقهبندی بر اساس قضیه بیز در احتمال ساخته شده است. بخواهیم ساده توضیح دهیم، در این الگوریتم فرض میشود که وجود یک ویژگی خاص در یک کلاس با وجود هیچ ویژگی دیگری ارتباط ندارد. یعنی؛ هر ویژگی مستقل از دیگر ویژگیها است و برای فهمیدن کلاس یک داده احتمال هر ویژگی را جداگانه حساب میکند.
به عنوان مثال، اگر گیاهی دارای برگهای دندانهدار، گلهای قرمز و بزرگ باشد، مدل بیز ساده احتمال بالایی را برای گل رز بودن گیاه پیشبینی میکند، حتی اگر این ویژگیها به یکدیگر بستگی داشته باشند، یک طبقهبندی ساده بیز همه این ویژگیها را به طور مستقل در احتمال رز بودن بودن این گیاه در نظر میگیرد.
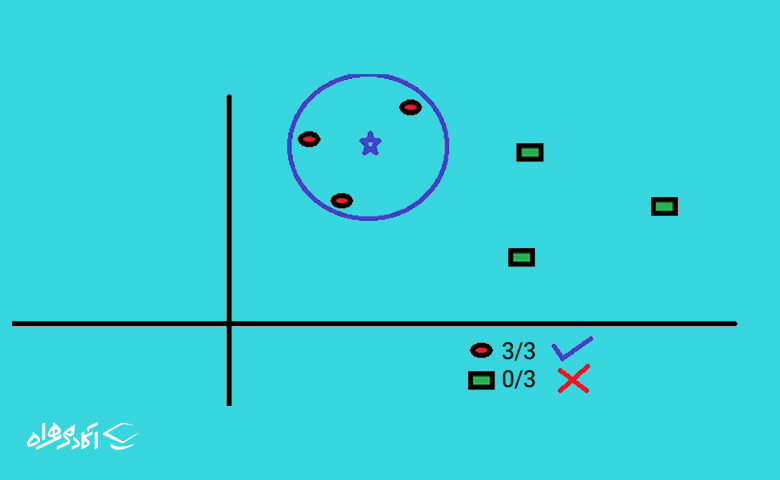
نزدیکترین همسایه KNN یکی دیگر از الگوریتم های یادگیری ماشین است که هم در مسائل رگرسیون و هم طبقهبندی کاربرد دارد. ایده اصلی الگوریتم این است که یک نمونه جدید را با توجه به نزدیکترین نمونههای آموزشی که از قبل طبقهبندی شدهاند؛ طبقهبندی میکند. تعداد نمونههای مورد بررسی هم K نامیده میشود. برای مثال اگر K را ۴ انتخاب کنیم، این الگوریتم ۴ نمونه نزدیک به داده ما را چک میکند و باتوجه به اینکه اکثر آنها در چه کلاسی قرار دارند، کلاس داده موردنظر را هم مشخص میکند.
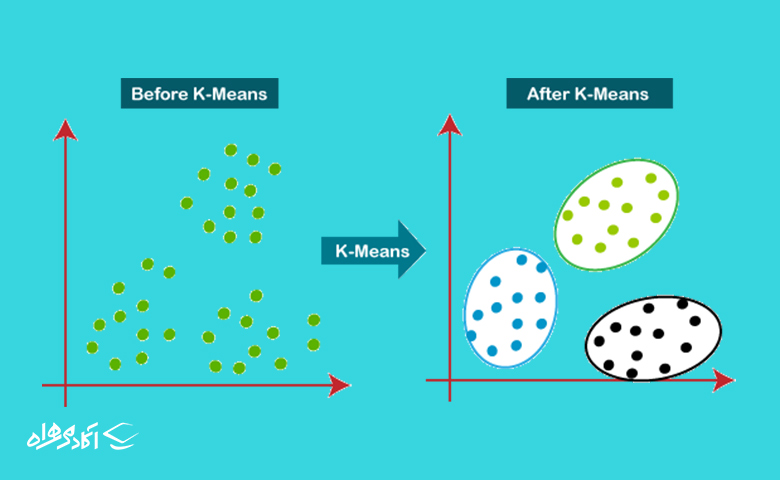
یکی از الگوریتم های یادگیری ماشین بدون نظارت که سعی در حل کردن مشکلات خوشهبندی دارد K-Means است. این الگوریتم دادهها را به k خوشه تقسیم میکند. ایده الگوریتم مثل الگوریتم KNN این است که هر داده را به نزدیکترین خوشه از نظر هندسی اختصاص بدهد.
برای مثال، فرض کنید مجموعه دادهای از نقاط داده در فضای دو بعدی داریم که میخواهیم این دادهها را به سه خوشه تقسیم کنیم. الگوریتم k-means ابتدا سه نقطه داده را تصادفی بهعنوان مرکز خوشهها انتخاب میکند. سپس، هر داده را به نزدیکترین خوشه نزدیک به خودش اضافه میکند و مرکز خوشهها را براساس میانگین جدید بهروز میکند. این فرآیند آنقدر تکرار میشود تا مراکز خوشهها بدون تغییر باقیبماند.
این الگوریتم راهحلی برای مشکلات الگوریتم یادگیری ماشین درخت تصمیم است که هم برای طبقهبندی و هم رگرسیون استفاده میشود.
سیستم کار به این صورت است که بجای استفاده از یک درخت از چند درخت تصمیم استفاده میشود (اسم جنگل هم از همینجا آمده است) و در آخر هر درخت رای خود را برای طبقهبندی و یا رگرسیون اعلام میکند و نتیجه میانگین رای درختان است.
برای مثال فرض کنید میخواهیم نوع یک میوه را بر اساس جنگل تصادفی مشخص کنیم اگر از سه درخت تصمیم استفاده کنیم و دو تا از آنها رای به نارنگی بودن میوه بدهند و یکی به آناناس بودن، جواب آخر الگوریتم به سوال نوع میوه، نارنگی است.
الگوریتم apriori اوایل دهه ۱۹۹۰ برای کشف ارتباط دادههای مختلف ابداع شد. این الگوریتم که جزو الگوریتم های یادگیری ماشین بدون نظارت است، در تشخیص الگوی و پیشبینی خرید مشتریها خوب کار میکند. برای مثال اگر افراد زیادی هنگام خرید مربا، کره هم بخرند این سیستم متوجه ارتباط شده و به خریدار بعدی مربا هوشمندانه پیشنهاد میکند کره هم بخرد.
این الگوریتم اطلاعات کشف شدهاش را در یک پایگاه داده رابطهای ذخیره میکند و مواردی که باهم زیاد تکرار میشوند را بهصورت قانون تعریف میکند. در مثال بالا الگوریتم قانونی تولید میکند که خریدار مربا احتمال خرید کره را زیاد میکند.
این الگوریتم یکی از الگوریتم های یادگیری عمیق است که از چند لایه مختلف تشکیل شده است و بیشتر برای پردازش تصویر و تشخیص اشیا استفاده میشود. ابداع اولیه این الگوریتم در سال ۱۹۸۸ برای تشخیص کاراکترهای کد پستی و اعداد بوده است.
CNN از سه لایه مختلف زیر تشکیل شده است:
یکی از بحثهایی که جدیدا در محافل زیادی مطرح میشود، جایگزینی شغلی انسانها توسط هوشمصنوعی است، اما تا به حال فکر کردهاید چطور میشود بجای ترسیدن از این تکنولوژی با آن همراه شویم و آینده شغلی خوبی برای خودمان رقم بزنیم؟
اگر بهدنبال راهی هستید که این الگوریتم های ماشین لرنینگ را بهراحتی و بهصورت کامل یاد بگیرید تا بتوانید بهعنوان یک دانشمند داده مشغول به کار شوید، پیشنهاد ما به شما بوتکمپ پایتون و هوشمصنوعی آکادمی همراه است.
این بوتکمپ نه تنها شامل یادگیری پایتون که یک زبان الزامی برای ورود به دنیای هوشمصنوعی است، بلکه از دانش ریاضی لازم برای یک متخصص واقعی شدن گرفته تا پردازش تصویر، متن، صوت و ….را یاد میگیرید.
۶ استاد مجرب شما را در این بوتکمپ همراهی میکنند تا مطمئن باشیم بهترین تدریس ممکن را خواهید دید.
اگر سوالی در مورد دوره دارید در کامنتها جوابگو شما عزیزان هستیم.
منابع:







