پردازش زبان طبیعی (NLP) چیست؟ + ۱۷ کاربرد ان ال پی
آیا تابهحال فکر کردهاید که چگونه رباتهایی مثل سوفیا یا دستیاران خانگی میتوانند شبیه یک انسان، با شما تعامل داشته باشند؟ همه اینها بهخاطر جادوی پردازش زبان طبیعی nlp است. با استفاده از ان ال پی میتوانید کاری کنید که ماشینها توانایی خواندن، درک و استخراج معنی از زبانهای انسانی را داشته باشند.
ازآنجایی که زبانهای انسانی شامل کلمات اختصاری، معانی مختلف، معانی فرعی، قواعد دستوری، زبان عامیانه و بسیاری از جنبههای دیگر میشود، درک آن برای رایانهها که فقط قابلیت تحلیل دادهها بهصورت ۰ و ۱ را دارند، بسیار دشوار است؛ بنابراین، دانشمندان به فکر ایجاد فناوریای افتادند که به ماشینها کمک کند تا زبانهای انسانی را رمزگشایی کرده و سریعتر آن را یاد بگیرند. همین امر مقدمهٔ پیدایش پردازش زبان طبیعی یا NLP شد.
اگر سوالاتی از قبیل nlp چیست یا علم nlp چیست و چه کاربردی دارد، در ذهنتان دارید، با کاملترین مقاله در مورد پردازش زبان طبیعی، قرار است به تمام جوابهایتان برسید. پس همراهمان باشید.
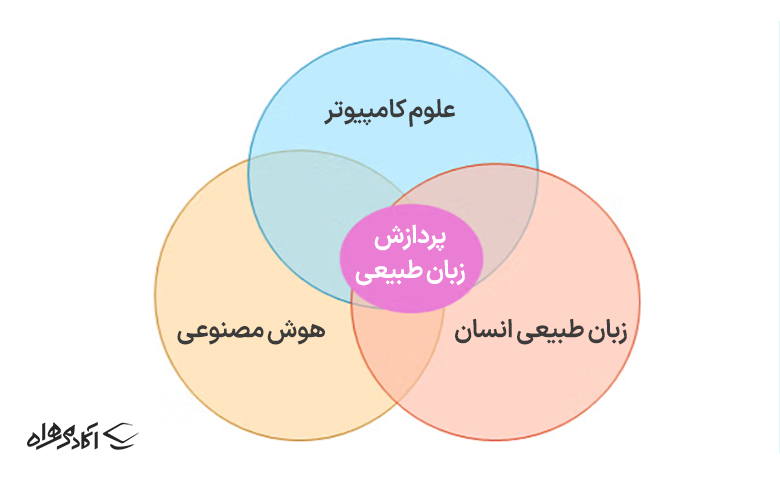
پردازش زبان طبیعی (Natural Language Processing/NLP) رشتهای از علوم کامپیوتر، زبانشناسی و هوش مصنوعی است که به تعامل بین زبان انسان و رایانه میپردازد و توانایی درک متن و کلمات گفتاری را به همان شیوهای که مغز انسان میتواند، به رایانه میدهد. ان ال پی به ماشینها کمک میکند تا بتوانند حجم زیادی از دادههای مرتبط با زبانهای طبیعی را تحلیل و پردازش کنند.
در یک کلمه، NLP شکاف تعامل بین انسان و دستگاههای الکترونیکی را پر میکند.
با ان ال پی، ماشینها میتوانند ترجمه، تشخیص گفتار، خلاصهسازی، تقسیمبندی موضوع و بسیاری از وظایف دیگر را از طرف توسعهدهندگان انجام دهند.
nlp همه کارها و وظایف را بهصورت در لحظه با استفاده از چندین الگوریتم انجام میدهد و زبانشناسی محاسباتی، یادگیری ماشینی و مدلهای یادگیری عمیق را برای پردازش زبان انسانی ترکیب میکند.
این فناوریها در کنار هم، رایانهها را قادر میسازند تا زبان انسان را که بهصورت متن یا دادههای صوتی است، پردازش کنند و معنای آن را کاملاً با هدف و احساسات گوینده یا نویسنده «درک» کنند. ان ال پی همچنین میتواند کلمات یا جملاتی را که هنگام نوشتن یا صحبت کردن به ذهن کاربر میآید، پیشبینی کند.
در ادامه توضیحی درباره کارکرد سه عامل مهم در پردازش زبان طبیعی میدهیم:
زبانشناسی محاسباتی (Computational linguistics)
زبانشناسی محاسباتی علم درک و ساختن مدلهای زبان انسانی با رایانه و ابزارهای نرمافزاری است. محققان از روشهای زبانشناسی محاسباتی مانند تحلیل نحوی و معنایی زبان، برای ایجاد چارچوبهایی استفاده میکنند که به ماشینها کمک میکند تا زبان مکالمه انسان را بفهمند. ابزارهایی مانند مترجم زبان، سینتسایزرهای تبدیل متن به گفتار و نرمافزارهای تشخیص گفتار بر اساس زبانشناسی محاسباتی هستند.
یادگیری ماشین (Machine learning)
زبان انسان دارای چندین ویژگی مانند طعنه یا لطیفه، استعاره، تغییرات در ساختار جمله، بهعلاوه دستور زبان و موارد استثنایی است که یادگیری آنها سالها طول میکشد. برنامهنویسان از روشهای یادگیری ماشینی برای آموزش برنامههای کاربردی NLP برای شناسایی و درک دقیق این ویژگیها استفاده میکنند. در این فناوری به رایانهها اجازه میدهند از دادهها یاد بگیرند و توانایی خود را برای درک متن یا دادههای صوتی بهطور مداوم بهبود بخشند.
یادگیری عمیق (Deep learning)
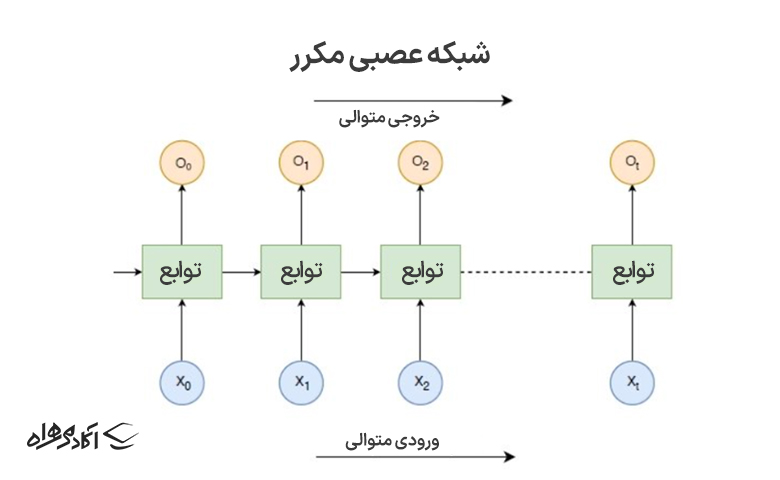
یادگیری عمیق یا دیپ لرنینگ زیرمجموعهٔ یادگیری ماشینی است که به رایانهها یاد میدهد مانند انسانها فکر کنند. این فناوری شامل یک شبکه عصبی است که از گرههایی شبیه مغز انسان تشکیل شده است. با یادگیری عمیق، رایانهها الگوهای پیچیده را در دادههای ورودی تشخیص میدهند، طبقهبندی میکنند و به هم مرتبط میسازند. یادگیری عمیق، بهویژه شبکههای عصبی مکرر (RNNs)، برای مدیریت و تجزیهوتحلیل دادههای متوالی مانند متن، سریهای زمانی، دادههای مالی، گفتار، صدا، ویدیو و سایر موارد ایدهآل است.
NLP را میتوان به دو زیرشاخه تقسیم کرد:
درک زبان طبیعی (NLU): بر تجزیهوتحلیل معنایی یا تعیین معنای مورد نظر متن و استخراج اطلاعات از آن تمرکز دارد.
تولید زبان طبیعی (NLG): بر تولید متن توسط یک ماشین تمرکز دارد. در این فرآیند ایجاد متن جدید از یک ورودی داده شامل گرفتن اطلاعات از یک منبع و تبدیل آن به متن قابل خواندن یا گفتاری است.
چرا ان ال پی اهمیت دارد؟
از اهمیت فناوری پردازش زبان طبیعی همینقدر بگوییم که طبق تحقیقاتِ Fortune Business Insights، پیشبینی میشود که بازار آمریکای شمالی برای NLP از ۲۴/۱۰ میلیارد دلار در سال ۲۰۲۳ به ۱۱۲/۲۸ میلیارد دلار در سال ۲۰۳۰ افزایش یابد.
چت رباتهای ان ال پی مانند ChatGPT ،محصول شرکت OpenAI، که در آن با استفاده از یادگیری عمیق به ورودیهایی با زبان طبیعی انسان، پاسخهایی انسانگونه داده میشود، فرصتهای مختلفی را برای کسبوکارها ارائه میکنند.
امروزه پردازش زبان طبیعی nlp در طیف وسیعی از زمینهها از جمله امور مالی، موتورهای جستجو، و هوش تجاری تا مراقبتهای بهداشتی و رباتیک کاربرد دارد و در تمام سیستمهای مدرن بهکار رفته است.
همچنین کسبوکارها، حجم عظیمی از دادههای بدون ساختار یا نیمهساختار یافته را با اطلاعات متنی پیچیده تولید میکنند که نیازمند روشهایی برای پردازش کارآمد است و تجزیهوتحلیل و پردازش این دادهها با اپراتورهای دستی غیرممکن است؛ بنابراین فناوری هوش مصنوعی بر پایه NLP برای درک مقادیر زیاد داده مورد نیاز است.
بهطور کلی، ان ال پی یک زمینهٔ به سرعت در حال توسعه است که پتانسیل ایجاد انقلابی بزرگ در نحوهٔ تعامل ما با رایانهها و دنیای اطراف را دارد.
این دو تعریف را بهخاطر بسپارید که به درک بهتر بخشهای بعدی کمک میکند:
تعریف زبان طبیعی
زبان طبیعی روشی است که انسانها با یکدیگر ارتباط برقرار میکنند. زبان انسان متشکل از کلمات و عباراتی است که ما در مکالمات روزمره از آنها استفاده میکنیم و میتوان از آن برای صحبت در مورد هر چیزی استفاده کرد. در زمینه NLP، زبان طبیعی دادههایی است که رایانهها سعی در درک آن دارند. این دادهها میتواند به صورت متن یا گفتار و به هر زبانی باشد.
پردازش در ان ال پی چیست؟
پردازش عبارت است از گرفتن دادهها و معنا بخشیدن به آن. این کار را میتوان به روشهای مختلفی انجام داد؛ اما هدف همیشه یکسان است: استخراج معنا از دادهها و تبدیل آن به چیزی که میتواند توسط رایانه استفاده شود.
پردازش زبان طبیعی چگونه کار میکند؟
بهطور معمول، پیادهسازی ان ال پی با جمعآوری و آمادهسازی دادههای متنی یا گفتاری بدون ساختار از منابعی مانند انبارهای دادهٔ ابری، نظرسنجیها، ایمیلها یا برنامههای داخلی فرآیندهای تجاری آغاز میشود.
پردازش زبان طبیعی طی دو مرحله، دادههای ورودی را به یک خروجی قابل درک تبدیل میکند: یکی پیشپردازش داده و دیگری توسعهٔ الگوریتم.
مرحله اول: پیشپردازش داده
در این مرحله دادههای متنیِ ورودی آماده و تمیز میشوند تا ماشین قادر به تجزیهوتحلیل آن باشد. پردازش دادهها روی متن ورودی کار میکند و آن را برای الگوریتمهای کامپیوتری مناسب میسازد. در واقع، مرحله پیشپردازش داده، دادهها را به شکلی آماده میکند که ماشین بتواند آن را درک کند.
نرمافزار NLP از تکنیکهای پیشپردازش داده برای آمادهسازی دادهها برای برنامههای مختلف استفاده میکند. اگر میپرسید تکنیک nlp چیست، در ادامه چند تکنیک برای پردازش دادهها آورده شده است:
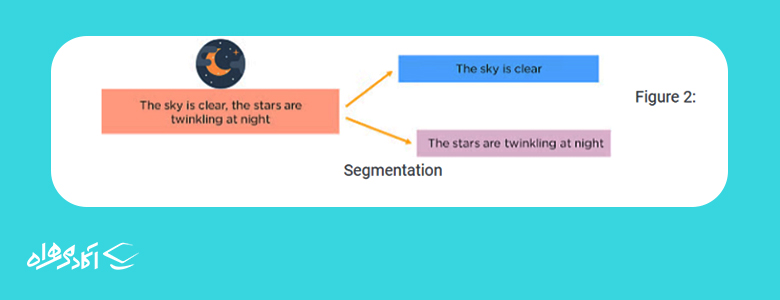
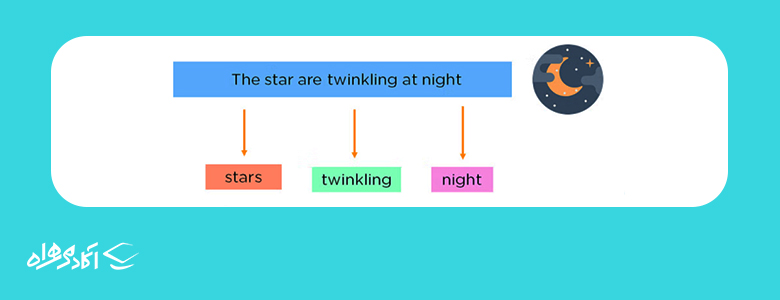
تقسیمبندی (Segmentation): در این تکنیک ابتدا کل سند به جملات تشکیلدهنده آن به همراه علائم نگارشی مانند نقطه و کاما تقسیم میشود.
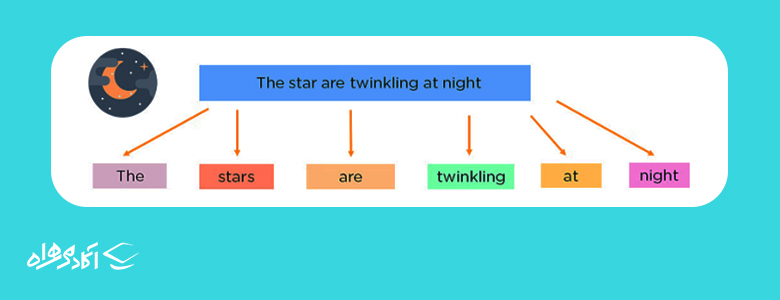
Tokenization: توکنسازی یک جمله را به واحدهای جداگانهٔ کلمات یا عبارات تقسیم میکند تا الگوریتم بتواند این جملات را بفهمد.
حذف کلمه توقف (Stop Word Removal):
این تکنیک با حذف کلمات غیرضروری که معنای قابل توجهی به جمله اضافه نمیکنند، (مثل in, is, the یا برای و با ) فرآیند درک زبان را سریعتر میکند.
ریشهیابی و واژهسازی (Stemming- Lemmatization)
در این روش کلمات به ساختار ریشه خود کاسته میشوند بهطوری که پردازش آنها برای ماشینها آسان باشد.
تکواژها کوچکترین عناصر معنادار زبان هستند. بهطور معمول تکواژها کوچکتر از کلمات هستند. بهعنوان مثال، «revisited» از پیشوند «re-»، ریشه «visit» و پسوند زمان گذشته «-ed» تشکیل شده است. ریشهبندی و واژهسازی کلمات را به شکلهای اصلی آنها نگاشت میکند (مثلاً «revisit» + گذشته).
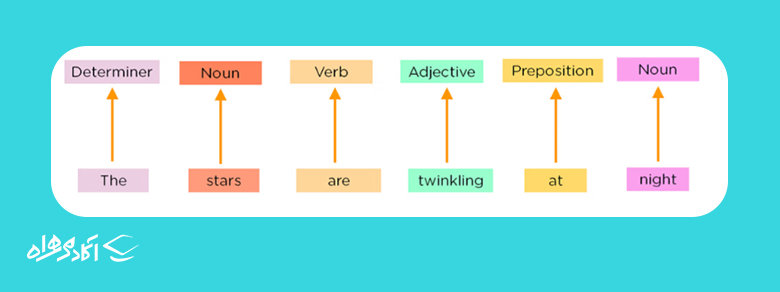
برچسب گذاری قسمتی از گفتار (Part of Speech Tagging)
به این ترتیب کلمات ورودی بر اساس اسم، صفت و افعال علامتگذاری و سپس پردازش میشوند.
شناسایی موجودیت نامگذاری شده (Named Entity Tagging)
در این مرحله، فرآیند شناسایی و دستهبندی موجودیتهای نامگذاری شده، مانند افراد، مکانها و سازمانها، نام فیلمها، شخصیتها یا مکانهای مهم و غیره که ممکن است در متن وجود داشته باشد، انجام میشود تا با طبقهبندی کلمات در زیر مجموعهها، دستگاه خود را با ارجاعات فرهنگ مردم و نامهای روزمره آشنا کند. زیرمجموعهها عبارتاند از: شخص، مکان، ارزش پولی، کمیت، سازمان، فیلم و غیره. این کار به پیدا کردن هر کلمه کلیدی در یک جمله کمک میکند.
مرحله دوم: آموزش الگوریتم یا مدلهای پردازش زبان طبیعی
پس از اینکه دادههای ورودی پیشپردازش شدند، سپس ماشین الگوریتمی را توسعه میدهد که درنهایت میتواند برنامهٔ ان ال پی را اجرا کند. آموزش و توسعهٔ الگوریتمهای nlp نیازمند تغذیهٔ نرمافزار با نمونه دادههای بزرگ برای افزایش دقت الگوریتمها است.
در میان تمام الگوریتمهای NLP که برای پردازش کلماتِ پیشپردازش شده کاربرد دارند، بهطور گسترده از سیستمهای مبتنی بر قانون و مبتنی بر یادگیری ماشینی استفاده میشوند:
سیستمهای مبتنی بر قانون (Rule-Based Systems)
در اینجا، سیستم از قواعد دستور زبان برای پردازش نهایی کلمات استفاده میکند. این یک الگوریتم قدیمی است که هنوز در مقیاس بزرگ مورد استفاده قرار میگیرد.
سیستمهای مبتنی بر یادگیری ماشین (Machine Learning-Based Systems)
این یک الگوریتم پیشرفته است که شبکههای عصبی، یادگیری عمیق و یادگیری ماشین را ترکیب میکند تا قانون خود را برای پردازش کلمات تعیین کند. ازآنجایی که از روشهای آماری استفاده میکند، الگوریتم براساس دادههای آموزشی برای پردازش کلمات تصمیم میگیرد و در ادامه تغییرات را ایجاد میکند. در واقع در این روش ماشینها از دادههای قبلی یاد میگیرند و خروجی نهایی را پیشبینی میکنند.
دستهبندی الگوریتمهای پردازش زبان طبیعی
الگوریتمهای ان ال پی، دستورالعملهای مبتنی بر ML یا ماشین لرنینگ هستند که هنگام پردازش زبانهای طبیعی استفاده میشوند. آنها به توسعه پروتکلها و مدلهایی میپردازند که ماشین را قادر میسازد زبانهای انسانی را تفسیر کند.
الگوریتمهای پردازش زبان طبیعی میتوانند شکل خود را با توجه به رویکرد هوش مصنوعی و همچنین دادههای آموزشیای که با آن تغذیه شدهاند، تغییر دهند. کار اصلی این الگوریتمها استفاده از تکنیکهای مختلف برای تبدیل موثر ورودیهای گیجکننده یا بدون ساختار به اطلاعاتی است که ماشین میتواند از آنها بیاموزد.
الگوریتمهای nlp به سه دسته مختلف تقسیم میشوند که در ادامه آوردهایم:
۱. الگوریتمهای نمادین (Symbolic Algorithms)
الگوریتمهای نمادین مسئول تجزیهوتحلیل معنای هر متن ورودی و سپس استفاده از آن برای ایجاد رابطه بین مفاهیم مختلف هستند.
۲. الگوریتمهای آماری (Statistical Algorithms)
این الگوریتم به ماشینها کمک میکند تا با تشخیص الگوها و روندها در مجموعه متون ورودی، زبان انسان را بیاموزند. این تجزیهو تحلیل به ماشینها کمک میکند تا پیشبینی کنند که کدام کلمه احتمالاً بعد از کلمه فعلی در لحظه نوشته میشود.
۳. الگوریتمهای ترکیبی (Hybrid Algorithms)
این نوع الگوریتم NLP قدرت هر دو الگوریتم نمادین و آماری را برای ایجاد یک نتیجه موثر ترکیب میکند. با تمرکز بر مزایا و ویژگیهای اصلی، میتواند بهراحتی حداکثر ضعف هر یک از روشها را که برای دقت بالا ضروری است، خنثی کند.
در اینجا بهترین الگوریتمهای ان ال پی وجود دارند که میتوانید استفاده کنید:
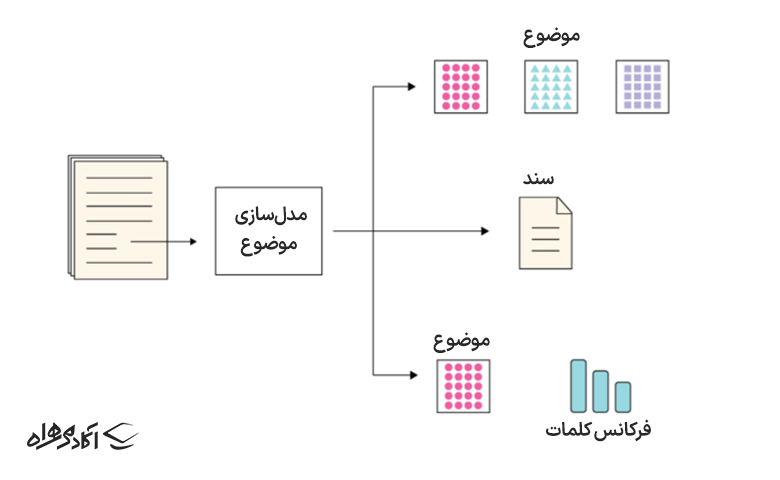
۱. مدلسازی موضوع (Topic Modeling)
این الگوریتم از تکنیکهای آماری nlp برای یافتن مضامین یا موضوعات اصلی از مجموعه عظیمی از اسناد متنی استفاده میکند. در واقع به ماشینها در یافتن موضوعی که میتواند برای تعریف یک مجموعه متن خاص استفاده شود؛ کمک میکند.
از آنجایی که هر مجموعهای از اسناد متنی موضوعات متعددی در خود دارد، این الگوریتم از هر تکنیک مناسبی برای یافتن هر موضوع با ارزیابی مجموعههای خاصی از واژگان کلمات استفاده میکند.
۲. خلاصهسازی متن (Text Summarization)
این الگوریتم یک متن را به شیوهای روان خلاصه میکند. این یک فرآیند سریع است زیرا خلاصهسازی به استخراج تمام اطلاعات ارزشمند بدون نیاز به مرور هر کلمه، کمک میکند.
خلاصهسازی را میتوان به دو صورت انجام داد:
خلاصهسازی مبتنی بر استخراج (Extraction-based summarization): در این روش، دستگاه فقط کلمات و عبارات اصلی را بدون تغییر نسخه اصلی از سند استخراج میکند.
خلاصهسازی مبتنی بر انتزاع (Abstraction-based summarization): در این فرآیند، کلمات و عبارات جدیدی از سند متن ایجاد میشود که تمام اطلاعات و هدف را به تصویر میکشد.
۳. تحلیل احساسات (Sentimental Analysis)
این الگوریتم NLP به ماشین کمک میکند تا معنی یا هدف پشت یک متن را از کاربر درک کند و در مدلهای مختلف هوش مصنوعی کسبوکار استفاده میشود؛ زیرا به شرکتها کمک میکند تا درک کنند که مشتریان در مورد محصولات یا خدماتشان چه احساسی دارند.
۴. استخراج کلمه کلیدی (Keyword Extraction)
این الگوریتم کلمات کلیدی معنیدار یا عبارات مهم را از متن استخراج میکند تا به شناسایی موضوعات یا گرایشها کمک کند. میتوان از آن برای شناسایی موضوعات در اسناد، پستهای وبلاگ و صفحات وب، بهینهسازی موتورهای جستجو (SEO)، نظارت بر مکالمات مشتری و شناسایی فرصتهای بالقوه در بازار استفاده کرد.
۵. نمودارهای دانش (Knowledge Graphs)
این الگوریتم یک شبکه نموداری از موجودیتهای مهم مانند افراد، مکانها و چیزها ایجاد میکند. سپس میتوان از این نمودار برای درک چگونگی ارتباط مفاهیم مختلف استفاده کرد.
نمودار دانش یک الگوریتم کلیدی کمک به ماشینها برای درک متن و معناشناسی زبان انسانی است. این بدان معنی است که ماشینها را قادر به درک تفاوتهای ظریف و پیچیدگیهای زبان میکند.
۶. TF-IDF
TF-IDF یک الگوریتم آماری پردازش زبان طبیعی است که در ارزیابی اهمیت یک کلمه برای یک سند خاصِ متعلق به یک مجموعه عظیم، مهم است. این تکنیک شامل ضرب مقادیر متمایز است که عبارتند از:
فرکانس اصطلاح (Term frequency): مقدار فرکانس اصطلاح یا عبارت، تعداد کل دفعاتی که یک کلمه در یک سند خاص آمده است را به شما نشان میدهد. بهطور کلی کلمات توقف در یک سند دارای فرکانس بالا هستند.
بسامد معکوس سند (Inverse document frequency): از سوی دیگر بسامد معکوس سند، عباراتی را که در یک سند بسیار خاص هستند یا کلماتی که کمتر در مجموعه کاملی از اسناد وجود دارند را برجسته میکند.
۷. ابر کلمات (Words Cloud)
این الگوریتم شامل تکنیکهایی برای تجسم دادهها میشود. در این الگوریتم کلمات مهم برجسته شده و سپس در جدولی نمایش داده میشوند. کلمات ضروری در سند با حروف بزرگتر چاپ شده، درحالیکه کلمات کم اهمیت با فونتهای کوچک نشان داده میشوند.
ابر کلمه یک نمایش گرافیکی از فراوانی کلمات استفاده شده در متن است. میتوان از آن برای شناسایی روندها و موضوعات در بازخورد مشتری استفاده کرد.
کاربردهای پردازش زبان طبیعی
NLP در موارد متفاوتی کاربرد دارد. برخی از محبوبترین آنها عبارتاند از:
فیلترهای هرزنامه (Spam Filters)
یکی از آزاردهندهترین موارد در مورد ایمیل، هرزنامه است. Gmail از پردازش زبان طبیعی برای تشخیص اینکه کدام ایمیلها مشروع و کدامیک هرزنامه هستند، استفاده میکند. این فیلترهای هرزنامه به متن تمام ایمیلهایی که دریافت میکنید نگاه میکنند و سعی میکنند معنی آن را بفهمند که آیا هرزنامه است یا نه.
معاملات الگوریتمی (Algorithmic Trading)
معاملات الگوریتمی برای پیشبینی شرایط بازار سهام استفاده میشود. پردازش زبان طبیعی با این فناوری عناوین اخبار مربوط به شرکتها و سهام را بررسی کرده و تلاش میکند تا معنای آنها را درک کند که آیا باید سهام خاصی را بخرید، بفروشید یا نگهداری کنید. در معاملات تریدینگ فارکس، این الگوریتمها بسیار کاربرد دارند.
پاسخگویی به سوالات (Questions Answering)
کاربرد پردازش زبان طبیعی را میتوان با استفاده از جستجوی Google یا خدمات Siri (دستیار دیجیتال گوشیهای آیفون) در عمل مشاهده کرد؛ بنابراین یکی از نقشهای کلیدی NLP این است که موتورهای جستجو معنای آنچه را که میپرسیم بفهمند و برای پاسخگویی به ما آن را به زبان طبیعی تبدیل کنند.
تصحیح خطای گرامری (Grammatical error correction)
با استفاده از مدلهای nlp قواعد گرامری را برای تصحیح دستور زبان در متن کدگذاری میکنند. برای این کار یک مدل بر روی یک جمله غیر دستوری بهعنوان ورودی و یک جمله صحیح بهعنوان خروجی آموزش داده میشود. چککنندههای دستور زبان آنلاین مانند Grammarly و سیستمهای پردازش کلمه مانند Microsoft Word از چنین سیستمهایی استفاده میکنند تا تجربه نوشتن بهتری را به مشتریان خود ارائه دهند. مدارس همچنین از آنها برای نمره دادن به مقالات دانش آموزان استفاده میکنند.
بهینهسازی موتور جستجو (SEO)
NLP ابزاری عالی برای کسب رتبهٔ بالاتر در جستجوی آنلاین با تجزیهوتحلیل جستجوها برای بهینهسازی محتوای شما است. دانستن نحوه استفاده موثر از این تکنیکها باعث میشود رتبه بالاتری از رقبای خود کسب کنید.
خدمات مشتری خودکار (Automated customer service)
چتباتهای مجهز به ان ال پی میتوانند تعداد زیادی از وظایف معمولی که امروزه توسط عوامل انسانی انجام میشود را پردازش کرده و زمان کارمندان را آزاد کنند تا روی کارهای چالشبرانگیزتر و جالبتر کار کنند. بهعنوان مثال، رباتهای چت و دستیاران دیجیتال میتوانند طیف گستردهای از درخواستهای کاربر را تشخیص دهند، آنها را با ورودی مناسب در پایگاه داده شرکت تطبیق دهند و پاسخ مناسب را برای کاربر فرموله کنند.
تجزیهوتحلیل احساسات (Sentiment analysis)
NLP میتواند برای تجزیهوتحلیل دادههای متنی و استخراج اطلاعات برای انجام تجزیهوتحلیل احساسات و شناسایی نظرات بیان شده استفاده شود. این مورد میتواند برای تحقیقات بازار، ردیابی رضایت مشتری یا نظارت بر مکالمات شبکههای اجتماعی استفاده شود.
طبقهبندی متن (Text classification)
از nlp میتوان برای طبقهبندی خودکار دادههای متنی به دستهها برای مدیریت اسناد، تشخیص هرزنامه، نظارت بر شبکههای اجتماعی، تعدیل محتوا یا سیستمهای پیشنهاد استفاده کرد.
سیستمهای تشخیص صدا (Voice recognition systems)
سیستمهای تشخیص صدا، گفتار به متن و پاسخ در برنامههایی مانند الکسا، سیری و دستیار گوگل استفاده میشوند که کاربران میتوانند با برنامه صحبت کنند و برنامه تشخیص دهد که چه میگویند.
ترجمه ماشینی (Machine translation)
ترجمه ماشینی در برنامهها و سرویسهایی مانند Google Translate، DeepL یا Linguee استفاده میشود که میتوانیم متن را از یک زبان به زبان دیگر ترجمه کنیم.
تعامل انسان-رایانه (Human-Computer Interaction)
ترکیب NLP با بینایی کامپیوتری (Computer Vision) میتواند نتایج بسیار قدرتمندی به همراه داشته باشد. nlp به رایانهها کمک میکند تا متن یا دادههای صوتی را درک کنند؛ در حالی که بینایی رایانه به آنها اجازه میدهد تا ادراک بصری، تفسیر و تجزیهوتحلیل تصاویر را انجام دهند. وقتی این دو فناوری با هم استفاده میشوند، ماشین نهتنها میتواند آنچه گفته میشود را بفهمد، بلکه میتواند جهان را بهگونهای ببیند که به آن واکنش هم نشان دهد.
کاربردهای پردازش زبان طبیعی در صنایع
در اینجا فقط چند نمونه از کاربردهای عملی nlp آورده شده است:
مراقبتهای بهداشتی: از آنجایی که سیستمهای مراقبتهای بهداشتی در سراسر جهان به سمت سوابق پزشکی الکترونیکی میروند، با حجم زیادی از دادههای بدون ساختار مواجه میشوند. ان ال پی میتواند برای تجزیهوتحلیل و به دست آوردن بینشهای جدید در مورد سوابق سلامت استفاده شود.
حقوقی: اغلب وکلا برای یک پرونده باید ساعتها را صرف بررسی مجموعههای بزرگ اسناد و جستجوی مطالب مرتبط با یک پرونده خاص کنند. فناوری ان ال پی میتواند فرآیند کشف قانونی را خودکار کند و با بررسی حجم زیادی از اسناد، زمان و خطای انسانی را کاهش دهد.
امور مالی: دنیای مالی بسیار سریع حرکت میکند و هر مزیت رقابتی مهم است. معاملهگران از فناوری NLP برای استخراج خودکار اطلاعات از اسناد و اخبار شرکتها برای استخراج اطلاعات مرتبط با پورتفولیو و تصمیمات تجاری خود استفاده میکنند.
خدمات مشتری: بسیاری از شرکتهای بزرگ از دستیاران مجازی یا رباتهای گفتگو برای کمک به پاسخگویی به سوالات اولیه مشتری و درخواستهای اطلاعاتی (مانند سؤالات متداول) استفاده میکنند و در صورت لزوم سؤالات پیچیده را به انسانها منتقل میکنند.
بیمه: شرکتهای بزرگ بیمه از nlp برای بررسی اسناد و گزارشهای مربوط به خسارتها استفاده میکنند تا روشی را که در کسبوکار انجام میشود را سادهتر کنند.
مزایا و محدودیتهای پردازش زبان طبیعی
در اینجا برخی از مهمترین مزایای پردازش زبان طبیعی آورده شده است:
مزایا
افزایش کارایی + مقرونبهصرفه بودن
استفاده از پردازش زبان طبیعی برای درک زبان و خودکار کردن وظایف معمول، مانند ترجمه زبان، استخراج اطلاعات، پاسخگویی به مشتریان از طریق چتباتها و تجزیهوتحلیل مقادیر زیادی از دادههای متنی، نیاز به کار دستی را کاهش میدهد و در زمان و هزینه سازمانها صرفهجویی میشود.
بهبود ارتباطات
مدلهای ان ال پی به افراد کمک میکنند تا ارتباط موثرتری با رایانهها و ماشینها برقرار کنند و فناوری را برای همه در دسترستر میکنند.
دقت بهتر
با استفاده از الگوریتمها برای درک تفاوتهای ظریف زبان، NLP میتواند نتایج دقیقتری نسبت به انسانها ارائه دهد، بهویژه زمانی که نوبت به تجزیهوتحلیل مقادیر زیادی داده میشود.
بهبود تجربه مشتری
با فناوری nlp میتوان با پشتیبانی شخصی و بهموقع مشتری، تجربه و رضایت کلی مشتری را بهبود بخشند.
تجزیهوتحلیل روشنگرانه و بصیرتی
پردازش زبان طبیعی میتواند به سازمانها کمک کند تا از دادههای بدون ساختار، مانند بازخورد مشتری، پستهای شبکههای اجتماعی و بررسیهای آنلاین، بینشی کسب کنند که میتواند به آنها در تصمیمگیری مبتنی بر داده و درک بازار هدف کمک کند.
محدودیتهای ان ال پی
با اینکه از پردازش زبان طبیعی میتوان برای طیف گستردهای از برنامهها استفاده کرد؛ اما هنوز کامل نیست. در واقع، بسیاری از ابزارهای NLP برای تفسیر کنایه یا لطیفه، احساسات، زبان عامیانه، متن نوشته، خطاها و انواع دیگر جملات مبهم باید پیشرفتهتر شوند. این بدان معناست که nlp عمدتاً در موقعیتهای بدون ابهام که نیاز به تفسیر قابل توجهی ندارند، کارایی بهتری دارد تا زمانی که کار کمی پیچیدهتر میشود.
آنها همچنین تمایل دارند که علیه گروههای خاصی از مردم (مانند زنان یا اقلیتها) تعصب داشته باشند و این مسئله به دلیل نحوهٔ آموزش مدلهای ان ال پی در مجموعه دادههایی است که منعکسکنندهٔ این سوگیریها هستند. تمام اینها محدودیتهایی است که امروزه در فناوری ان ال پی با آن مواجهیم.
پردازش زبان طبیعی با پایتون
پایتون بهترین زبان برنامهنویسی برای ان ال پی به دلیل طیف گستردهای از ابزارها و کتابخانهها، سهولت استفاده و پشتیبانی توسط جامعه بزرگی از برنامهنویسان است؛ همچنین بهعنوان یکی از مبتدیترین زبانهای برنامهنویسی در نظر گرفته میشود که یادگیری NLP را برای تازهکارها ایدهآل میکند؛ بنابراین آموزش پردازش زبان طبیعی با پایتون بهترین انتخاب است.
NLTK یا (Natural Language Toolkit) شامل کتابخانههایی بهصورت Open source است که بسیاری از وظایف nlp را در بر میگیرد.
پایتون کتابخانههایی برای وظایف فرعی، مانند تجزیه جملات، تقسیمبندی کلمات، ریشهیابی، واژهسازی و نشانهسازی و همینطور پیادهسازی قابلیتهایی مانند استدلال معنایی، توانایی رسیدن به نتایج منطقی بر اساس حقایق استخراجشده از متن دارد.
سوالی که ممکن است در اینجا بپرسید این است که آیا امکان پردازش زبان فارسی با پایتون هم وجود دارد؟
در پاسخ باید بگوییم که پردازش زبان طبیعی فارسی با زبان برنامهنویسی پایتون و کتابخانه قدرتمند NLTK و استفاده از کتابخانههای فارسی که در این برنامه موجود است، امکانپذیر است.
آکادمی همراه دورهای تحت عنوان بوتکمپ پایتون و هوش مصنوعی دارد که میتوانید با شرکت در آن آمادگی لازم را برای شرکت در دورههای پیشرفتهتر مثل پردازش زبان طبیعی را کسب کنید.
کارکردن در حوزهٔ nlp میتواند چالشبرانگیز و سودمند باشد؛ زیرا به درک خوبی از اصول محاسباتی و زبانی نیاز دارد. پردازش زبان طبیعی یک فناوری سریع و در حال تغییر است؛ بنابراین برای افرادی که در ان ال پی کار میکنند، مهم است که از آخرین پیشرفتها مطلع باشند.
شغلهای رایج در پردازش زبان طبیعی عبارتاند از:
مهندس NLP: طراحی و پیادهسازی سیستمها و مدلهای nlp؛
محقق NLP: انجام تحقیق در مورد تکنیکها و الگوریتمهای nlp؛
مهندس ML: طراحی و استقرار مدلهای مختلف یادگیری ماشین از جمله nlp؛
دانشمند داده NLP: تجزیهوتحلیل و تفسیر دادههای nlp؛
مشاور NLP: ارائه تخصص و مشاوره در حوزه nlp به سازمانها و مشاغل.
! آکادمی همراه با برگزاری دورهٔ آنلاین «تحلیلگر داده» طی ۸۰ ساعت آموزش تخصصی، شما را برای ورود به این مسیر شغلی همراهی میکند.
ورود به دنیای تکنولوژی با آموزش پردازش زبان طبیعی
با چشمانداز و پتانسیل آیندهٔ پیشرو، انتظار میرود که ابزارها و مدلهای ان ال پی هم به تکامل خود ادامه دهند و توانایی درک احساسات و مقاصد پیچیده انسانی را با دقت بیشتری داشته باشند. از طرفی با رشد سریع دادههای تولید شده توسط انسان، برای درک این دادهها و استخراج بینشهای ارزشمند از آنها، باز هم پای NLP وسط کشیده میشود.
تنها ابزاری که برای پیشگام شدن با این عصر تکنولوژی دارید، کسب دانش و بهروز کردن اطلاعات در این زمینه است. خوشبختانه در جای درستی هستید و اینبار هم برای شما دورهای فوقالعاده داریم.
اگر میخواهید بدانید که دورههای nlp چیست و بهچه صورت برگزار میشود، باید بگوییم که دوره پردازش زبان طبیعی در آکادمی همراه بهصورت آنلاین دایر است و با مبحث جذاب چتباتها طراحی شده است. در این دوره مباحث تئوری به همراه تمرین و پروژه گنجانده شده و همه شرایط فراهم است تا شما فقط یاد بگیرید و بهکار ببندید. امیدواریم نهایت استفاده را از آن ببرید.